In a previous blog, we discussed the performance of different programming models—SYCL, OpenMP, CUDA, and HIP—when applied to Computational Fluid Dynamics (CFD). In this article we will delve deeper into these three languages, comparing their pros and cons, installation requirements, and performance using a simple vector addition example.
GPU programming
CUDA has been the go-to language for GPU programming, especially for NVIDIA hardware. CUDA is probably the most well-known GPU language. It offers low-level hardware control and high performance but lacks portability across different GPU architectures. CUDA is a closed language and is only tied to NVIDIA GPUs.
On the other hand, SYCL and OpenMP are gaining traction due to their portability across different accelerators, especially for multi-vendor GPUs (NVIDIA, AMD, Intel). While they may not offer the same level of performance as CUDA, they provide a balance between performance and portability.
Setting Up Your Environment
To get started with these languages, you’ll need to set up the appropriate software stack:
– CUDA: Install the CUDA toolkit from the NVIDIA website. Make sure your NVIDIA GPU driver is also up to date.
– SYCL: You’ll need a SYCL-capable compiler like DPC++. The straightest solution is installing one API. In the case, you would like to make it compatible with NVIDIA and AMD GPUs, you also must install the associated plugins found in the Codeplay page.
– OpenMP: In the case of OpenMP, we should find a compiler with the ability to offload the code in our GPU. In the case of NVIDIA, the CUDA toolkit already has a compiler to compile OpenMP on this platform. The same is applicable for Intel GPUs (using oneAPI), and for AMD GPUs we must go with the vendor compiler installing the ROCm toolkit.
Time to code in our GPU
Let’s compare these languages using a simple vector addition operation. We’ll show the code for each language and how to compile it.
CUDA
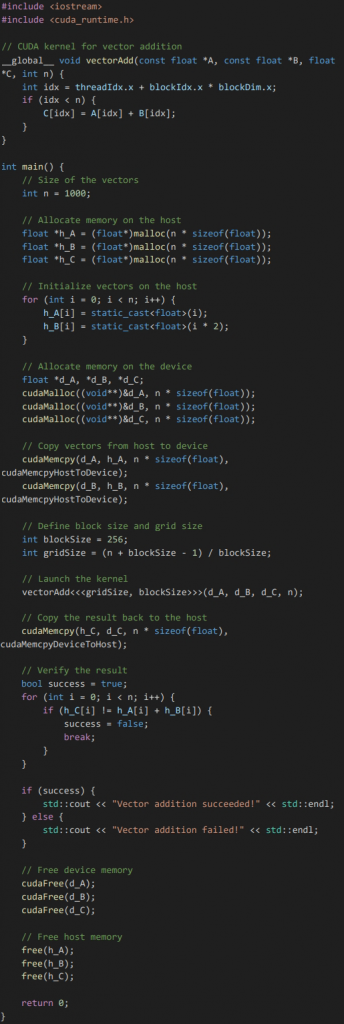
To compile: nvcc -O3 add.cu -o add
SYCL
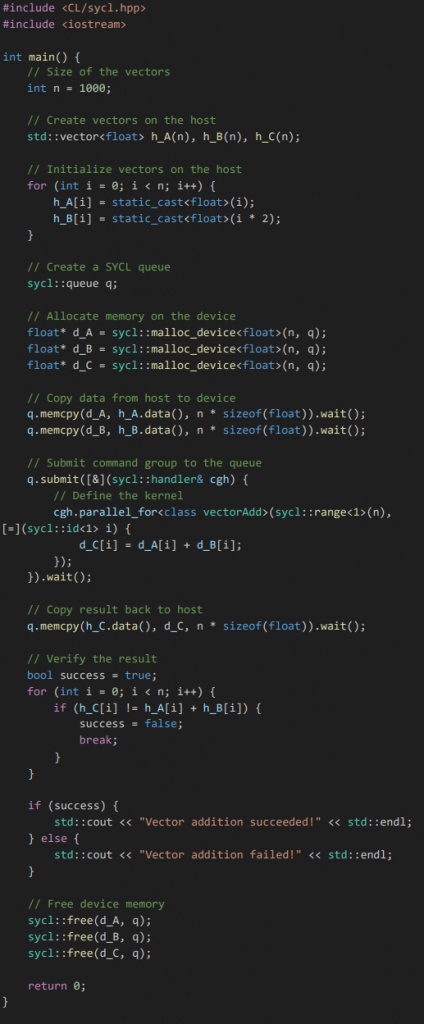
To compile for NVIDIA’s GPU: icpx -fsycl -O3 -fsycl-targets=nvptx64-nvidia-cuda -o add add.cpp
OpenMP
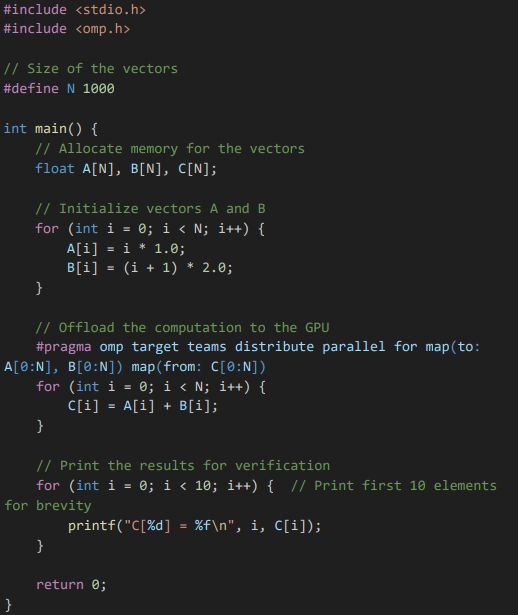
To compile with CUDA: nvc++ -mp -gpu=cc70 -o add add.cpp
Conclusion
Choosing between CUDA, SYCL, and OpenMP depends on your specific needs and the hardware at your disposal. While CUDA might offer superior performance on NVIDIA hardware, SYCL and OpenMP provide the advantage of portability across different GPU architectures. As always, the best way to decide is to test these languages with your specific use case. Happy coding!
This blog article was written by our partner, Atos and Youssef El Faqir El Rhazoui.
Stay tuned with us by subscribing to our newsletter and checking all the updates on our social media.
Follow us on social media:
Linkedin | @HiDALGO2
X (Twitter) | @HiDALGO2_EU
Facebook | @Hidalgo2 EU Project
Youtube | @HiDALGO